
C++ 性能优化总结
2021年4月26日 星期一, 发表于 东莞,中国
如果你对本文有任何的建议或者疑问, 可以在 这里提issues
[TOC]
工作以来,似乎做过的每个项目都离不开性能优化这个点,内存,CPU,系统资源,执行速度等等KPI是我们永远绕不过去的性能指标,正好碰上这两天脱产接受了关于C++性能优化的培训,结合自己的经验和培训内容大胆地总结一下关于C++性能优化的方方面面。当然,可能由于作者的水平有限,如果有错误或者遗漏请大家指出。
哲学篇
Premature optimization is the root of all evil.
过早优化是万恶之源,现如今这个思想应该是被程序员广泛认可的,这句话最早出现在1960年Donald Knuth的经典《计算机程序设计艺术 》中,书中的完整表达是这样的:
“The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.”
正如作者所言,过早优化会让程序员浪费太多时间在不必要的事情身上。所以首先明确一点,性能优化应该发生在真正出现性能问题的时候或者是对性能有真实诉求的当下,而不是在臆想中。
有一个典型的例子是,一家初创公司花费大量时间试图弄清楚如何扩展其软件以处理数百万个用户。这确实是一个非常需要考虑但不一定要付诸行动的问题。但是在担心要处理数百万个用户之前,它需要先确保有100个用户喜欢并想要使用它的产品。所以首先聆听用户的反馈,再决定性能优化是不是你必要的动作。
注:杠精请不要说那我是不是可以一开始的时候也不需要多加考虑写很低效的代码。如果有这种抬杠思想,那么这篇文章不适合您阅读,请节省您的时间不要继续往下阅读。
概念篇
计算机体系架构和性能
Memory hierarchy
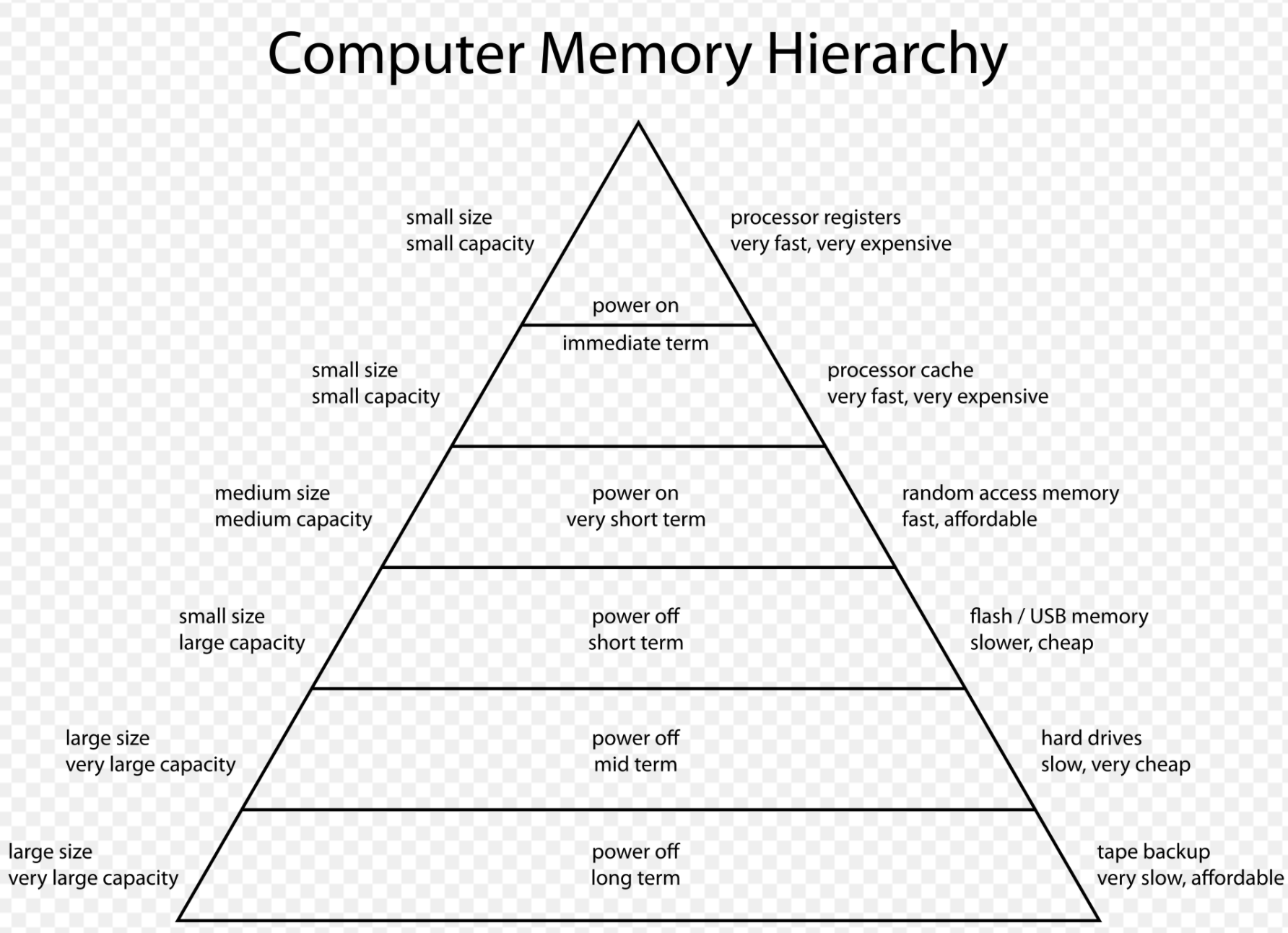
对于通用计算机而言,存储层次分为四层:
- Internal – Processor registers and cache.
- Main – the system RAM and controller cards.
- On-line mass storage – Secondary storage.
- Off-line bulk storage – Tertiary and Off-line storage.
当然,这是相对通用的内存层次结构,还有许多其他结构也是有用的。例如,在设计计算机体系结构时,可以将分页算法视为虚拟内存的一种级别,其中一种可以包括在线和离线存储之间的近线存储级别。
随着时间的推移,内存层次结构中的层数以及每个层次的性能都得到了提高。以Inter Hasweill i7-4770的存储层次为例,大家可以看到从寄存器到各级缓存到外设的访问速度是越来越慢,而价格也越来越低:
| 名称 | 大小 | 延迟 |
|---|---|---|
| 寄存器 | ~1KB | — |
| L0(微码)缓存 | 6KB | — |
| L1缓存 | 32KB数据+32KB指令 | 4-5始终周期(数据) |
| L2缓存 | 256KB | 12时钟周期(~4纳秒) |
| L3缓存(4核共享) | 8MB | 36时钟周期(~10纳秒) |
| 主存 | 32GB(最大;~$3/GB) | ~67纳秒 |
| 固态盘 | 256GB(典型;~$0.2/GB) | ~30微秒 |
| 硬盘 | 2TB(典型; ~$0.05/GB) | ~15毫秒 |
| 磁带(现在还有人用吗?) | 15TB(典型;~$0.01/GB) | 无随机访问能力 |
很显然,单纯从内存层次来看,性能优化就是一场金钱游戏,当然如果大家都不考虑成本的话,就没有后面这么多事了,要搞性能优化的程序员们一般都是掉进了要使用更便宜的硬件但是还要获得更好性能的泥潭中,所以接着往下看吧!
大多数现代CPU处理速度非常快,以至于对于大多数程序而言,瓶颈在于内存访问的引用位置以及层次结构不同层次之间的缓存和内存传输效率上。这有时被称为空间成本,因为较大的存储对象更可能超出小/快速的内存层级,并需要使用大/慢的内存层级。由此导致的内存使用负载被称之为压力(分别是寄存器压力,高速缓存压力和(主)内存压力)。较高级别的数据丢失并且需要从较低级别的数据获取的术语分别是:寄存器溢出(register spilling,寄存器到高速缓存),高速缓存未命中(cache miss,高速缓存到主内存,缓存的命中率通常是90%+)和页面错误(page fault,主内存到磁盘)。
现代编程语言主要假设内存的两个级别,即主内存和磁盘存储,尽管在汇编语言和以C等语言进行的内联汇编程序中,可以直接访问寄存器。要充分利用内存层次结构,需要程序员,硬件和编译器的合作(以及操作系统的基础支持):
- 程序员负责通过文件I/O在磁盘和内存之间移动数据
- 硬件负责在内存和缓存之间移动数据
- 优化编译器负责生成能够在执行时让硬件更有效使用缓存和寄存器的代码
处理器的乱序执行和流水线
我们知道,在cpu中为了能够让指令的执行尽可能地并行起来,从而发明了流水线技术。但是如果两条指令的前后存在依赖关系,比如数据依赖,控制依赖等,此时后一条语句就必需等到前一条指令完成后,才能开始。cpu为了提高流水线的运行效率,会做出比如:1)对无依赖的前后指令做适当的乱序和调度;2)对控制依赖的指令做分支预测;3)对读取内存等的耗时操作,做提前预读等等。以上总总,都会导致指令乱序。
但是对于x86的cpu来说,在单核视角上,其实它做出了Sequential consistency的一致性保障。Sequential consistency的在wiki上的定义如下:
“… the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.”
也就是说,要满足Sequential consistency,必需保障每个处理器的指令执行顺序必需和程序给出的顺序一致。奇怪吧?这不就和我刚才说的指令乱序优化矛盾了嘛?其实并不矛盾,指令在cpu核内部确实是乱序执行和调度的,但是它们对外表现却是顺序提交的。如果把ISA寄存器(如EAX,EBX等)和store buffer,作为cpu对外的接口的话,cpu只需要把内部真实的物理寄存器按照指令的执行顺序,顺序映射到ISA寄存器上,也就是cpu只要将结果顺序地提交到ISA寄存器,就可以保证Sequential consistency。
当然,以上是对x86架构的cpu来说的,ARM/Power架构的cpu在单核上的一致性保证要弱一些,无需保证Sequential consistency,因此也不需要顺序提交,只需保证控制依赖,数据依赖,地址依赖等指令的顺序即可。要想在这些弱一致性模型cpu下保证无关指令间的提交顺序,需要使用barrier指令。
流水线和乱序执行可以提高每个时钟周期的处理能力,而分支可能打乱流水线,造成性能下降。
C++知识点
内存管理和对象的生命周期
栈内存的特性
- 分配极为简单,移动一下栈指针而已
- 当前函数执行完即自动释放
- 后进先出,不可能出现内存碎片
- 函数返回后,栈上对象即被销毁
- 栈内存不分享,栈上对象通常没有多线程竞争问题
堆内存的特征
- 分配和释放算法较为复杂
- 可能出现内存碎片
- 内存分配和释放通常需要加锁
- 堆上对象在被释放前一直可以被适用
- 堆上对象有可能被多个线程访问,潜在有竞争问题
因此,对于堆内存的申请和释放要特别注意,需要配对调用,malloc/free,new/delete,fopen/fclose,当然在C++11出现智能指针以后这个工作就轻松很多了。
RAII(Resource Acquisition Is Initialization)
虽然RAII这个命名很奇怪,但在我看来RAII是C++中最独特的特性,RAII要求资源的有效期与持有资源的对象的生命期严格绑定,即由对象的构造函数完成资源的分配,同时由析构函数完成资源的释放。在这种要求下,只要对象能正确地析构,就不会出现资源泄露问题。利用RAII,你可以写出这样的代码:
1
2
3
4
5
std::mutex mtx;
void func(){
std::lock_guard<std::mutex> guard(mtx);
...
}
而不需要写这样的代码:
1
2
3
4
5
6
std::mutex mtx;
void func(){
mtx.lock();
...
mtx.unlock();
}
静态/全局对象
- 每进程单词创建销毁
- 访问通过指针,直接、迅速
- 多线程访问潜在有竞争可能性
thread local
- 每线程单词创建销毁
- 访问多一层,间接、略慢
- 没有多线程竞争问题
容器
vector
特点:
- 可以使用resize来改变其大小,成功后size()会改变
- 可以使用pop_back来删除最后一个元素,性能为O(1)
- 可以使用push_back在尾部插入一个元素,性能为分摊O(1)
- 可以使用insert在指定位置前插入一个元素,需要移动之后的所有元素
- 可以使用erase在指定位置删除一个元素,需要移动之后的所有元素
性能注意事项:
- 希望在内存重分配时使用元素的移动构造函数的话,必须声明为noexcept
- 使用reserve来减少保留内存,减少内存分配
- 尽量避免insert和erase,以免移动元素
deque
特点:
- 只从头、尾两个位置进行增删操作的话,容器里的对象永远不需要移动
- 提供push_front/emplace_front/pop_front成员函数,性能O(1)
- 容器里的元素只是部分连续(因而无法提供data成员函数)
- 由于元素的存储大部分仍然连续,遍历性能较高
- 支持使用下标访问容器元素,仍能保持O(1)
list
特点:
- 提供高效的、O(1)复杂度的任意位置的插入和删除操作
- 不适用某些标准算法,但提供成员函数作为替代(reverse, sort, …)
forward_list
- 支持insert_after,不支持insert
- 适用于小对象,内存占用小于list(每成员少一个指针)
在容器库的使用中,一般的容器都推荐使用标准库的实现,唯独unordered_map除外,业界有不少性能比标准库好的hash table实现:
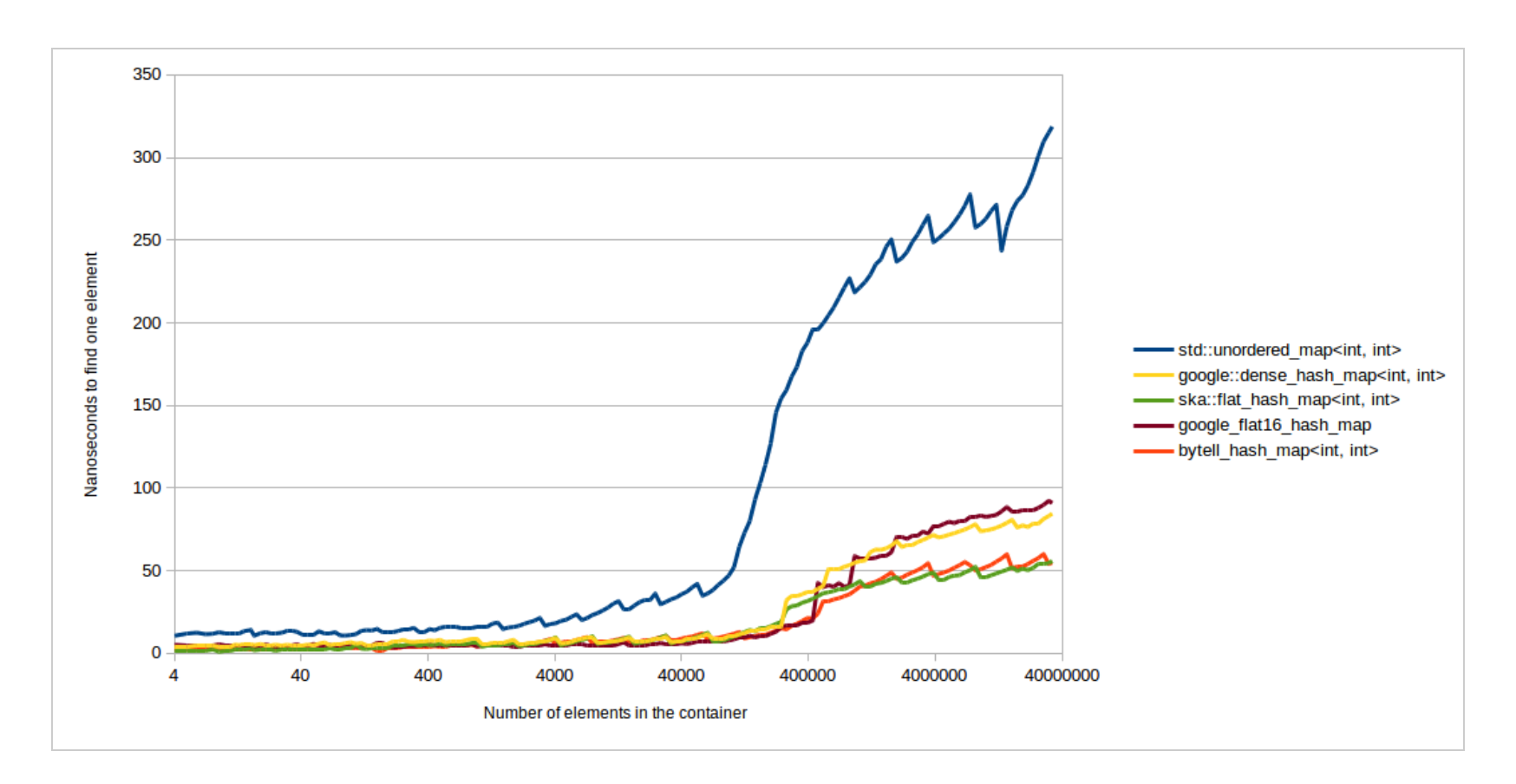
并发
原子操作
- 读:在读取的过程中,读取位置的内容不会发生任何变动
- 写:在写入的过程中,其他执行线程不会看到部分写入的结果
- 读-修改-写:读取内存、修改数值、然后写回内存,整个操作的过程中间不会有其他写入操作插入,其他执行线程不会看到部分写入的结果
内存序
C++11在标准库中引入了memory model,这应该是C++11最重要的特性之一。C++11引入memory model的意义在于我们可以在high level language层面实现对在多处理器中多线程共享内存交互的控制。我们可以在语言层面忽略compiler,CPU arch的不同对多线程编程的影响了,我们的多线程可以跨平台了。
C++11中提供了六种不同memory_order选项,不同的选项会定义不同的memory consistency类型。memory order指定了对应的对共享内存的operation order的关系,memory order也是一致性模型的一种反映。
-
memory_order_seq_cst:顺序一致性模型,这个是默认提供的最强的一致性模型。
- memory_order_acquire:来自不同线程的两个原子操作顺序不一定?那怎么能限制一下它们的顺序?这就需要两个线程进行一下同步(synchronize-with)。同步什么呢?同步对一个变量的读写操作。线程 A 原子性地把值写入 x (release), 然后线程 B 原子性地读取 x 的值(acquire). 这样线程 B 保证读取到 x 的最新值。
- memory_order_release
Acquire semantics: is a property that can only apply to operations that read from shared memory, whether they are read-modify-write operations or plain loads. The operation is then considered a read-acquire. Acquire semantics prevent memory reordering of the read-acquire with any read or write operation that follows it in program order. Release semantics: is a property that can only apply to operations that write to shared memory, whether they are read-modify-write operations or plain stores. The operation is then considered a write-release. Release semantics prevent memory reordering of the write-release with any read or write operation that precedes it in program order.
- memory_order_acq_rel
- memory_order_consume:在很多时候,线程间只想针对有依赖关系的操作进行同步,除此之外线程中的其他操作顺序如何无所谓。当代码的执行结果依赖于另一行代码的执行结果,此时称这两行代码之间的关系为“carry-a-dependency ”。C++中引入的memory_order_consume内存模型就针对这类代码间有明确的依赖关系的语句限制其先后顺序。
- memory_order_relaxed:在单个线程内,所有原子操作是顺序进行的。按照什么顺序?基本上就是代码顺序(sequenced-before)。这就是唯一的限制了!两个来自不同线程的原子操作是什么顺序?两个字:任意。
注意 release – acquire 有个很厉害的副作用:线程 A 中所有发生在 release x 之前的写操作,对在线程 B acquire x 之后的任何读操作都可见!本来 A, B 间读写操作顺序不定。这么一同步,在 x 这个点前后, A, B 线程之间有了个顺序关系,称作 inter-thread happens-before。
acquire和release可以通过添加memory barrier(fence)实现。
虽然共有 6 个选项,但它们表示的是三种内存模型:
- sequential consistent(memory_order_seq_cst)
- relaxed(memory_order_relaxed)
- acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel)
另外,内存模型定义了Synchronized-with 与 happens-before 关系:
-
Synchronized-with 关系:简单地说,如果线程 A 写了变量 x, 线程 B 读了变量 x, 那么我们就说线程 A, B 间存在 synchronized-with 关系。
-
Happens-before 关系:Happens-before 指明了哪些指令将看到哪些指令的结果。
对于单线程而言,这很明了。如果一个操作 A 排列在另一个操作 B 之前,那么这个操作 A happens-before B。但如果多个操作发生在一条声明中(statement),那么通常他们是没有 happens-before 关系的,因为他们是未排序的。当然这也有 例外,比如逗号表达式。
对于多线程而言,如果一个线程中的操作 A inter-thread happens-before 另一个线程中的操作B, 那么 A happens-before B。
留个作业:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
atomic<bool> f=false;
atomic<bool> g=false;
int n;
// thread1
n = 42; // op6
f.store(true, memory_order_release); // op1
// thread2
while(!f.load(memory_order_acquire)); // op2
g.store(true, memory_order_release); // op3
// thread3
while(!g.load(memory_order_acquire)); // op4
assert(42 == n); // op5
分析以上这段代码中的synchronize-with关系以及happends-before关系,最后回答assert(42 == n)结果是成功的吗?
双重检查锁定梗
使用并发编程后程序员不再能假设有”自然“的完全执行顺序,同时开发人员必须主动利用多核的特性,适用于单线程的接口可能不再适用,而多线程的调度和竞争成为影响性能的关键因素。
C++惯用法
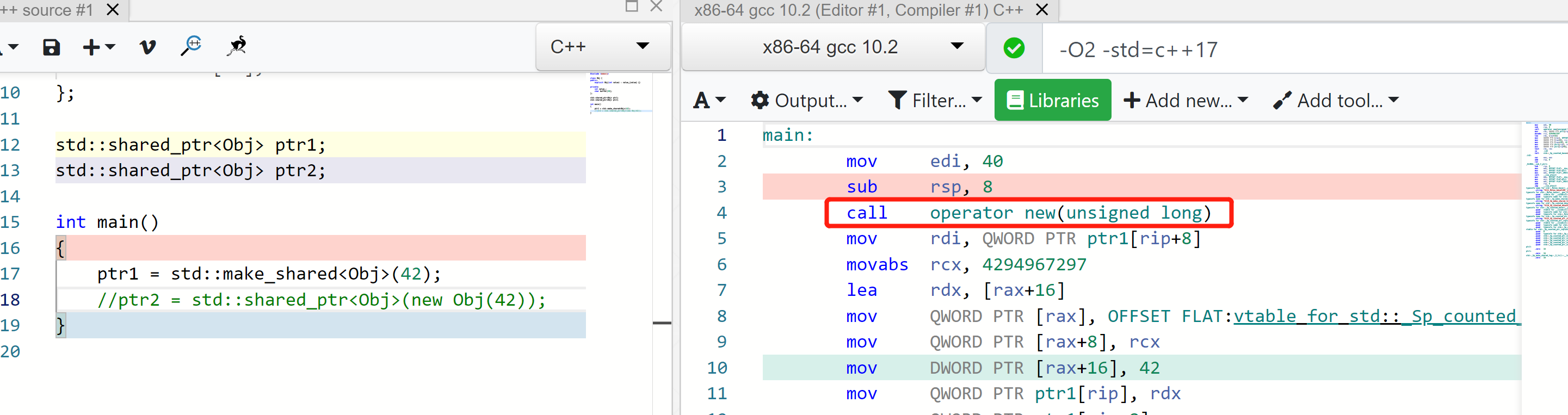
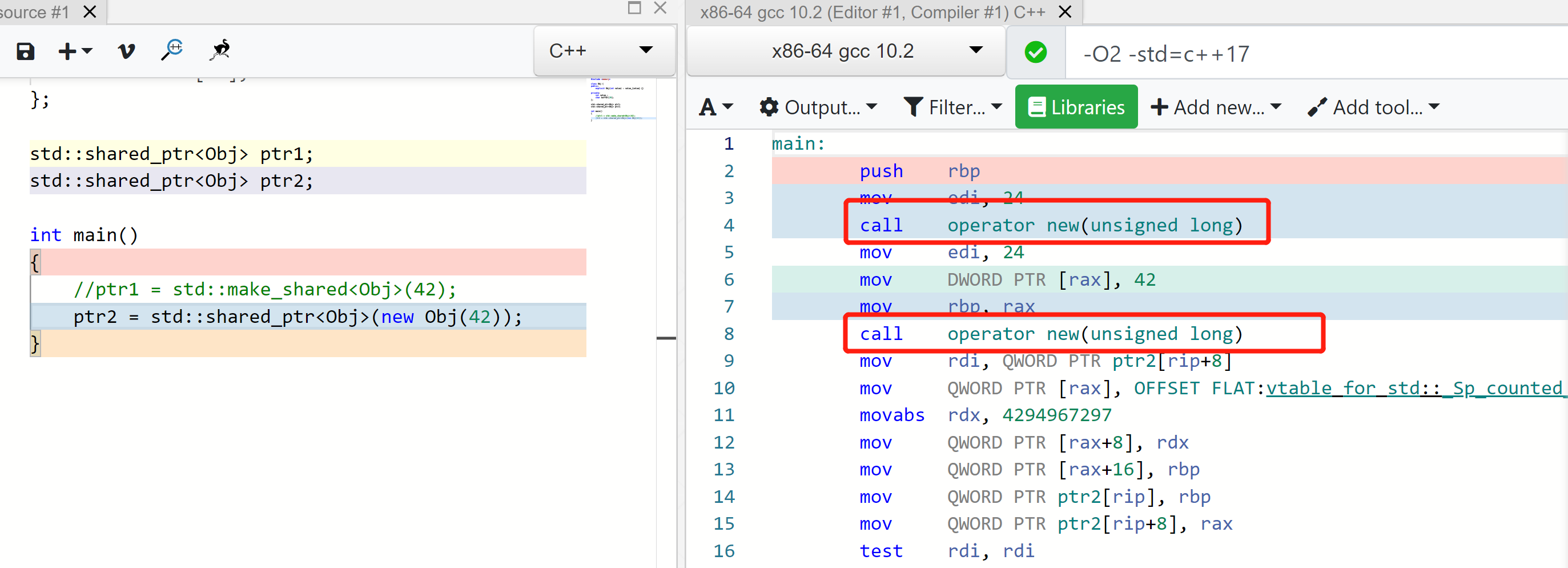
智能指针
1
2
3
4
// good
auto ptr = std::make_shared<Obj>(42);
// bad
std::shared_ptr<Obj> ptr{new Obj(42)};
ranges::view
- 不拥有指向的资源,需要在视图外部维护对象的生命周期
- 轻量,常常只是指针加长度(比使用指针更安全,不容易出错)
- 可以以O(1)开销进行复制
string_view
1
2
3
4
5
6
7
string generate_greeting(string_view name) {
string result("Hi, ");
result.append(name.data(), name.size());
return result;
}
generate_greeting("Horatio"); // 参数可以用string也可以用string_view
span
1
2
3
void analyse_sequence(span<int> sp);
int a[] = {1,2,3,4,5};
analyse_sequence(a); // vector<int> 和 array<int>都可以
控制流优化
- 尽量使用switch/case而不是if/else(编译器可能自动优化成表驱动)
- 尽量使用虚函数而不是switch/case(本质上转变为表驱动)
- 考虑使用模板或者if constexpr 代替虚函数(消除虚函数开销 & 允许内联优化)
浮点数表达式优化
- 把常量归并到一起
1
2
3
4
// good
(a * b) * x
// bad
a * x * b
- 手工简化表达式
1
2
3
4
// good
(a * x + b) * x + c
// bad
a * x^2 + b * x + c
- 除法优化
1
2
3
4
// good
x * (1 / a)
// bad
x / a
- 注意在有硬件浮点运算单元的机器上可能double比float快
输入输出优化
-
IOstreams可以满足大部分使用场景下的性能
-
使用std::ios::sync_with_stdio(false); 可以大幅提升cin和cout的性能
-
在POSIX规范中,getchar等宏/函数会自动进行多线程锁定,可能导致性能问题
解决方法1:使用getchar_unlocked等宏/函数
解决方法2: 一次读取较多内容,使锁定开销可忽略
解决方法3: 利用内存映射文件(MMAP)访问文件内容
多线程优化
- 能使用atomic就不要使用mutex
- 如果读比写多很多,使用读写锁(share_mutex)而不是独占锁(mutex)
- 使用线程本地(thread_local)变量
编译器优化
编译选项
- -O0(默认):不开启优化,方便功能调试
- -Og:方便调试的优化选项(比-O1更保守)
- -O1:保守的优化选项,当前GCC上打开了45个优化选项
- -Os: 产生小代码的优化选项(比-O2更保守,并往产生较小代码的方向优化)
- -O2:常用的发布优化选项(堆错误编码容忍度低),当前GCC上比-O1多打开48个优化选项,包括自动内联函数和严格别名规则
- -O3:较为激进的优化选项(对错误编码容忍度最低),当前GCC上比-O2多打开16个优化选项
- -Ofast:打开可导致不服可IEEE浮点数等标准的性能优化选项
PGO
- 首次编译加上–profile-generate(开启通常的优化选项)
- 典型场景测试运行
- 再次编译使用–profile-use
测试对比:
| 函数 | -O0 | -O2 | -O2 –profile-use | 总性能提升 |
|---|---|---|---|---|
| sort_with_less | 340981(1717) | 24414(333) | 11920(113) | 29x |
| sort_with_func | 334601(1843) | 46384(220) | 12953(267) | 26x |
| qsort_with_func | 133801(1814) | 85323(535) | 87089(905) | 1.5x |
不需要的优化
-
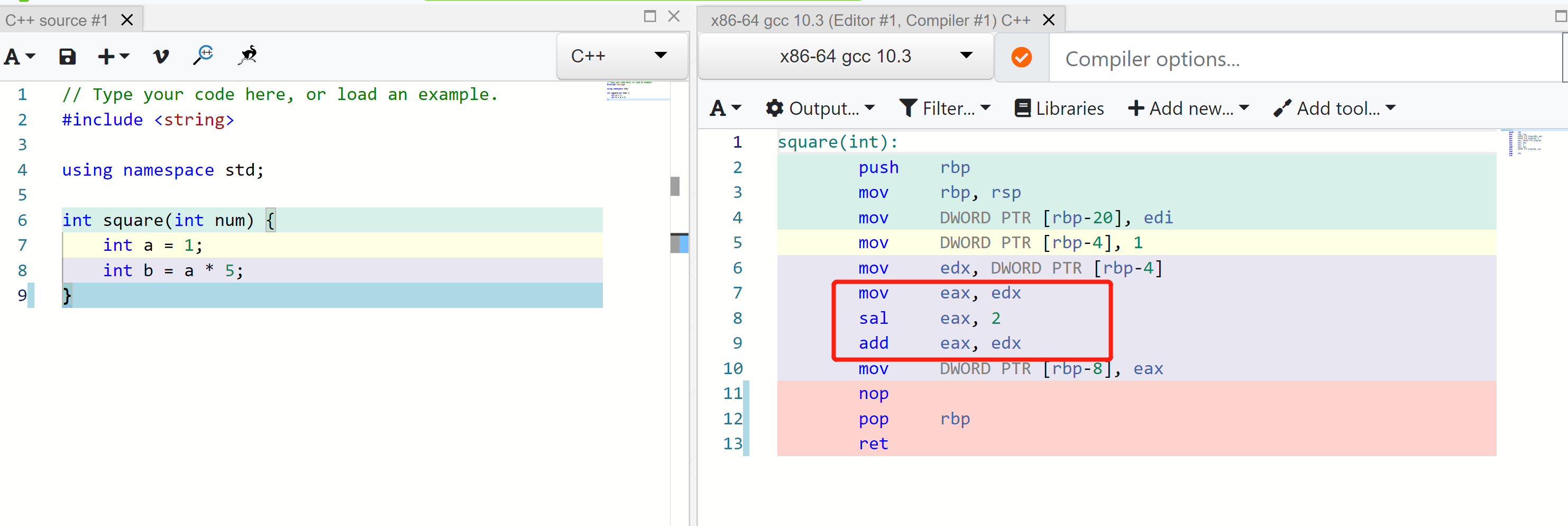
把 x*8 写成 x « 3; 或者把 x * 5 写成 (x « 2) + x
因为变乘为移动和加法是GCC在-O0时就会做的
来自C++ core guideline的性能优化建议
同样地,Bjarne和Herb在C++ core guideline中也给出了他们的C++性能优化哲学和建议:
Performance rule summary:
- Per.1: Don’t optimize without reason
- Per.2: Don’t optimize prematurely
- Per.3: Don’t optimize something that’s not performance critical
- Per.4: Don’t assume that complicated code is necessarily faster than simple code
- Per.5: Don’t assume that low-level code is necessarily faster than high-level code
- Per.6: Don’t make claims about performance without measurements
- Per.7: Design to enable optimization
- Per.10: Rely on the static type system
- Per.11: Move computation from run time to compile time
- Per.12: Eliminate redundant aliases
- Per.13: Eliminate redundant indirections
- Per.14: Minimize the number of allocations and deallocations
- Per.15: Do not allocate on a critical branch
- Per.16: Use compact data structures
- Per.17: Declare the most used member of a time-critical struct first
- Per.18: Space is time
- Per.19: Access memory predictably
- Per.30: Avoid context switches on the critical path
实践篇
在测试过程中要小心排除编译器,处理器以及测试工具可能造成的性能干扰,谨记先找到程序中的”瓶颈”,再对其进行优化,测试 – 记录 – 改进。
测试必知
RDTSC指令(Read Time Stamp Counter)
- x84和x64系统上的首选计时方式
- 主流编译器都提供内置函数__rdtsc,开发者不需要自行用内联汇编实现
- 较新的CPU一般提供constant_tsc功能,CPU频率变化不会影响TSC计时
- 较新的CPU一般提供nonstop_tsc功能,休眠不影响TSC计时
- 多核CPU一般能同步TSC,但多CPU插槽的系统该指令可能仍有不一致问题
-
TSC频率和CPU参考主频不一定一致(自行测量或使用dmesg grep ‘tsc.*MHz’)
处理器的重排序
在没有同步指令的情况下,处理器可以(通常为了性能)在(当前线程)结果不变的情况下自由地调整执行顺序
- 同步指令包括LOCK前缀、MFENCE指令等
- 顺序较为严格的x86处理器只会把较晚的LOAD指令移到较早的STORE之前
- 顺序较为松散的处理器(如ARM)会允许其他情况下的调整
- 对同一内存地址的修改,不同的CPU会看到相同的修改顺序
- 对不同内存地址的修改,不同的CPU可能看到不同的修改顺序
- volatile 声明对处理器的乱序执行没有影响
编译器的重排序
在没有同步原语的情况下,编译器可以(通常为了性能)在(当前线程)结果不变的情况下自由地调整执行顺序
- 同步原语包括互斥锁操作、内存屏障、原子操作等
- 局部变量可能被完全消除
- 全局变量只保证在下一个同步点到来之前写回到内存里
- volatile 声明可以禁止编译器进行相关的优化
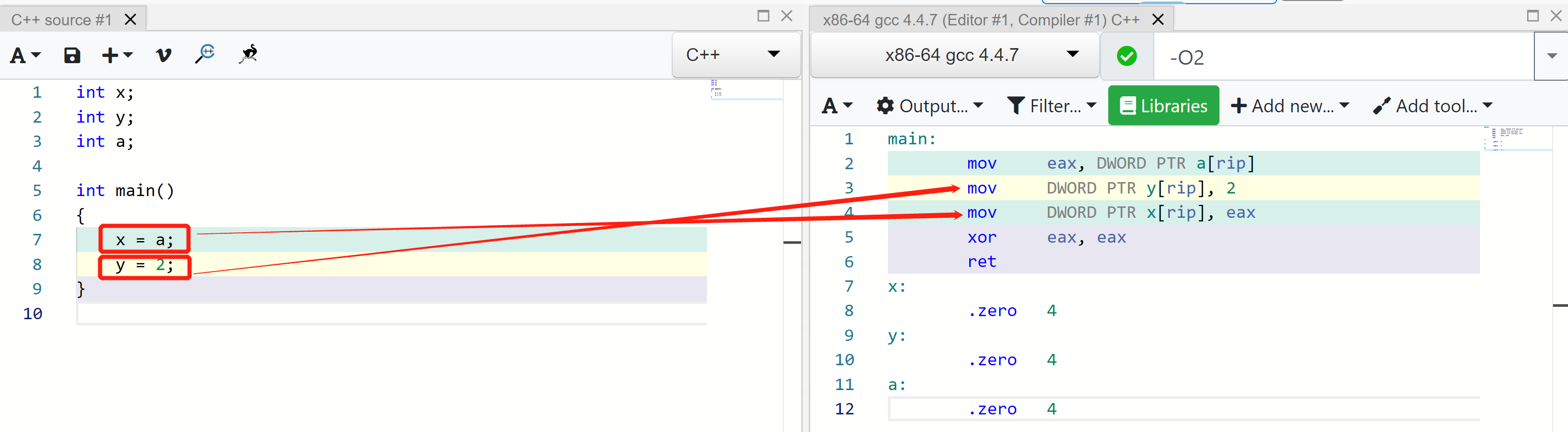
测试代码防优化技巧
- 使用全局变量避免被优化
- 使用锁来当作简单的内存屏障
- 避免使用volatile
- 可使用noinline来防止意外内联
两种性能测试方式
采样测试
- 总体开销可控
- 一般不影响程序“热点“
- 基于统计,误差较大
- 适用于寻找程序热点
- 可以完全在程序外部进行测试
插桩测试
- 开销随测试范围而变
- 插桩本身可能影响测试结果
- 测试结果可以较为精准、稳定
- 适合对单个函数进行性能调优
- 需要修改源代码或构建过程
测试工具
gprof 使用
g++ -O1 -g -pg …
./可执行程序
gprof 可执行程序 gmon.out > gprof.out
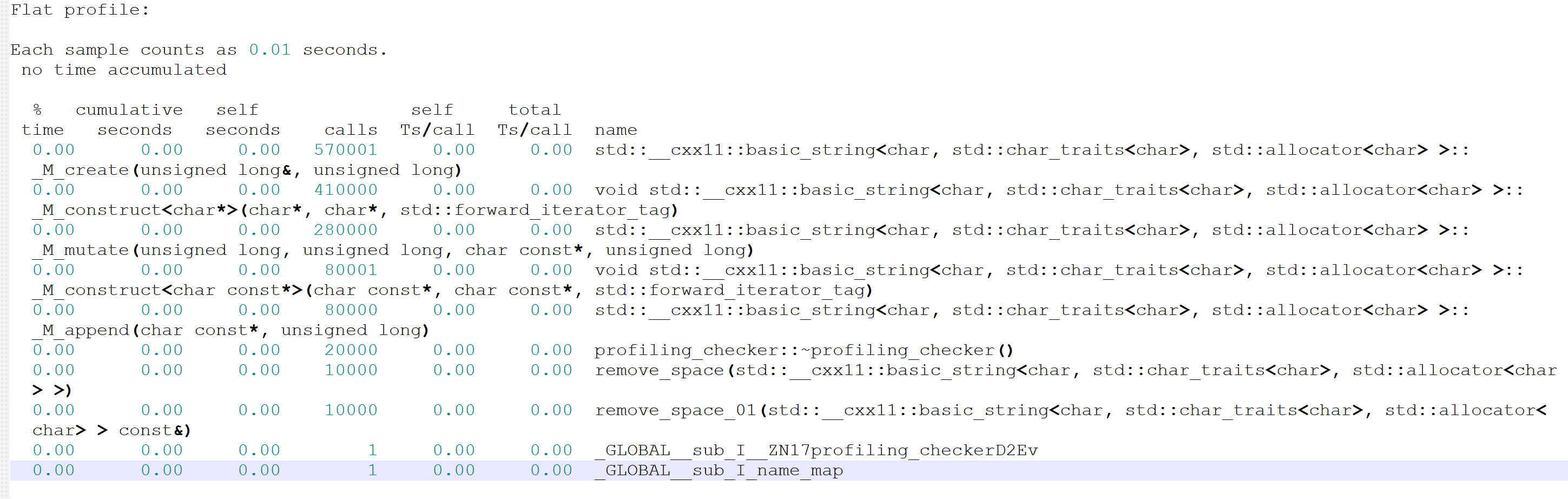
性能对比测试样例
函数和虚函数
- 虚函数多一重间接,可能略增加调用开销
- 虚函数通常会防止内联,这是它主要带来的性能问题